如果我们知道用户看过了哪些电影,我们可以使用此信息来推荐类似的电影:
2
3
4
5
6
7
8
MATCH (u:User {name: "Angelica Rodriguez"})-[r:RATED]->(m:Movie),
(m)-[:IN_GENRE]->(g:Genre)<-[:IN_GENRE]-(rec:Movie) WHERE NOT EXISTS( (u)-[:RATED]->(rec) )
WITH rec, [g.name, COUNT(*)] AS scores
RETURN rec.title AS recommendation, rec.year AS year,
COLLECT(scores) AS scoreComponents,
REDUCE (s=0,x in COLLECT(scores) | s+x[1]) AS score
ORDER BY score DESC LIMIT 10
返回结果如下:


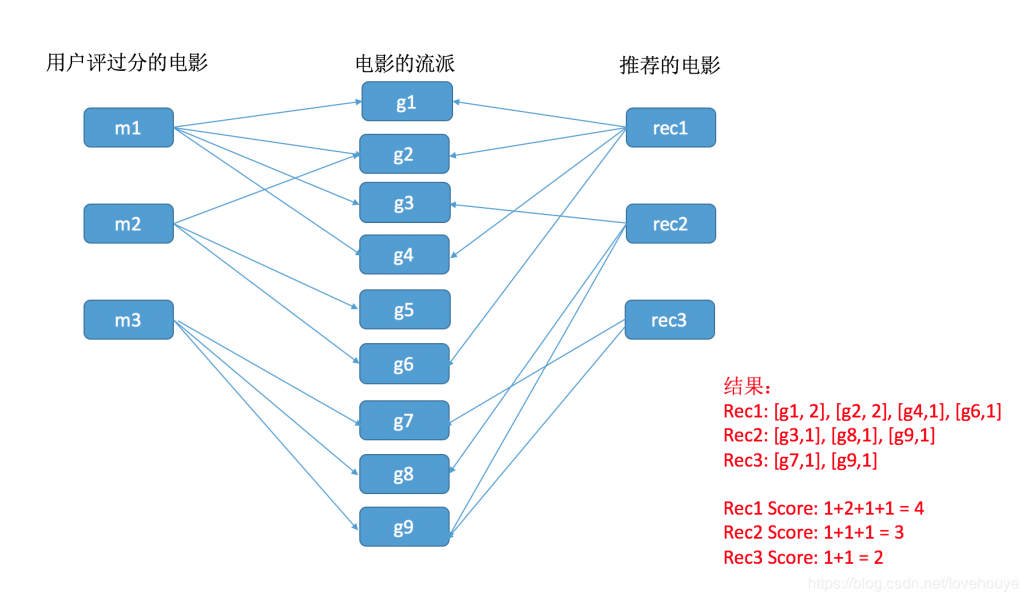
分析:
- 确定用户Angelica
- 找出用户评过分的电影m
- 把被评分的电影的流派找出来(g:Genre)
- 通过流派g再返回去搜索属于该流派的电影 (rec:Movie),并且是Angelica 没有评过分的那部分电影
- 返回电影,根据流派名称数量来打分 —— [g.name, COUNT(*)] AS scores
- 把Scores 列表中的数据列出来 —— COLLECT(scores) AS scoreComponents,
- 从Scores 列表中,把名称数量提取出来相加,作为得分 —— REDUCE (s=0,x in COLLECT(scores) | s+x[1]) AS score
- 按得分高低排序
这里运用到了几个函数和表达式:
1. [‘a’, ‘b’, ‘c’] AS list
Literal lists are declared in square brackets.
2. collect(n.property)
List from the values, ignores null.
3. reduce(s = “”, x IN list | s + x.prop)
Evaluate expression for each element in the list, accumulate the results.
备注:
[g.name, COUNT(*)] AS scores
这句话想了很久什么意思。因为最终是要返回rec 记录,假设我们已经找到了rec,那么rec 记录中的每一条,它的流派是清晰的。那么它的流派,在 m 中出现过多少次,就是 [g.name, count(*)] 的结果。

- Neo4j 做推荐 (1)—— 基础数据
- Neo4j 做推荐 (2)—— 基于内容的过滤
- Neo4j 做推荐 (3)—— 协同过滤
- Neo4j 做推荐 (4)—— 基于内容的过滤(续)
- Neo4j 做推荐 (5)—— 基于类型的个性化建议
- Neo4j 做推荐 (6)—— 加权内容算法
- Neo4j 做推荐 (7)—— 基于内容的相似度量标准
- Neo4j 做推荐 (8)—— 协同过滤(利用电影评级)
- Neo4j 做推荐 (9)—— 协同过滤(人群的智慧)
- Neo4j 做推荐 (10)—— 协同过滤(皮尔逊相似性)
- Neo4j 做推荐 (11)—— 协同过滤(余弦相似度)
- Neo4j 做推荐 (12)—— 协同过滤(基于邻域的推荐)
作者:imHou
来源:CSDN
原文:https://blog.csdn.net/lovehouye/article/details/83215494
版权声明:本文为博主原创文章,转载请附上博文链接!
在 “Neo4j 做推荐 (5)—— 基于类型的个性化建议” 上有 1 条评论
评论已关闭.