协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息
2
RETURN rec.title AS recommendation, COUNT(*) AS usersWhoAlsoWatched ORDER BY usersWhoAlsoWatched DESC LIMIT 25
执行结果是:
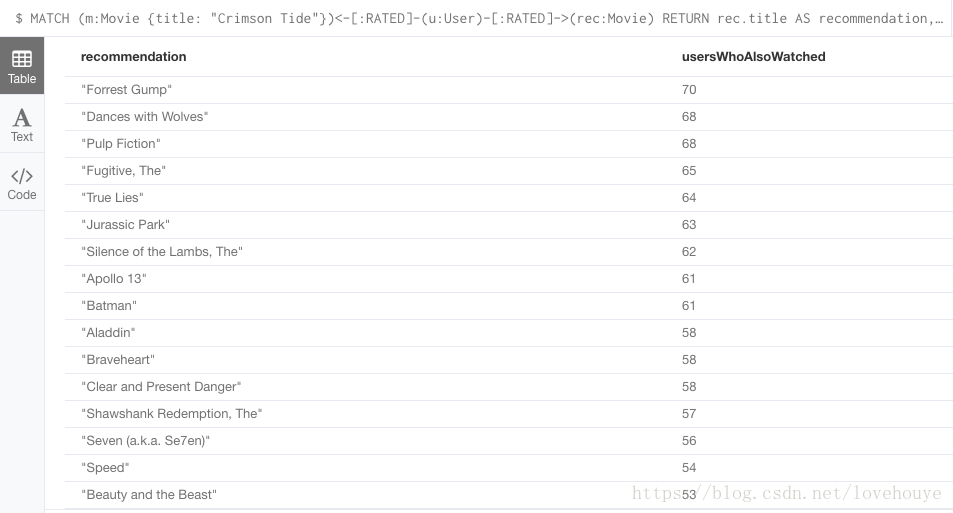
分析:
此Cypher 语句的意思是:找出对电影《Crimson Tide》 进行过评分的用户,还对哪些电影进行过评分?并对这些被评分的电影,进行评分次数的累加并排名。
这就是通过简单的协同过滤,来看拥有相同兴趣的用户,他们还有哪些共同的喜好。
当然目前这样处理,还不够严谨,后续我们会添加更多的条件或者指标权重加以调整。
- Neo4j 做推荐 (1)—— 基础数据
- Neo4j 做推荐 (2)—— 基于内容的过滤
- Neo4j 做推荐 (3)—— 协同过滤
- Neo4j 做推荐 (4)—— 基于内容的过滤(续)
- Neo4j 做推荐 (5)—— 基于类型的个性化建议
- Neo4j 做推荐 (6)—— 加权内容算法
- Neo4j 做推荐 (7)—— 基于内容的相似度量标准
- Neo4j 做推荐 (8)—— 协同过滤(利用电影评级)
- Neo4j 做推荐 (9)—— 协同过滤(人群的智慧)
- Neo4j 做推荐 (10)—— 协同过滤(皮尔逊相似性)
- Neo4j 做推荐 (11)—— 协同过滤(余弦相似度)
- Neo4j 做推荐 (12)—— 协同过滤(基于邻域的推荐)
作者:imHou
来源:CSDN
原文:https://blog.csdn.net/lovehouye/article/details/83027137
版权声明:本文为博主原创文章,转载请附上博文链接!
在 “Neo4j 做推荐 (3)—— 协同过滤” 上有 5 条评论
评论已关闭.