皮尔逊相似性或皮尔逊相关性是我们可以使用的另一种相似度量。这特别适合产品推荐,因为它考虑到不同用户将具有不同的平均评分这一事实:平均而言,一些用户倾向于给出比其他用户更高的评分。由于皮尔逊相似性考虑了均值的差异,因此该指标将解释这些差异。
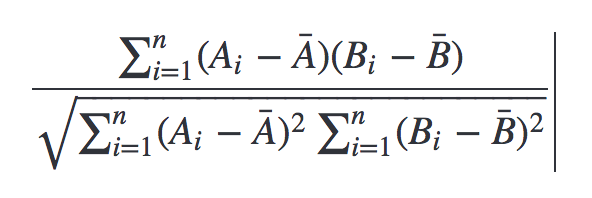
根据皮尔逊的相似度,找到与Cynthia Freeman最相似的用户
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
WITH u1, avg(r.rating) AS u1_mean
MATCH (u1)-[r1:RATED]->(m:Movie)<-[r2:RATED]-(u2)
WITH u1, u1_mean, u2, COLLECT({r1: r1, r2: r2}) AS ratings WHERE size(ratings) > 10
MATCH (u2)-[r:RATED]->(m:Movie)
WITH u1, u1_mean, u2, avg(r.rating) AS u2_mean, ratings
UNWIND ratings AS r
WITH sum( (r.r1.rating-u1_mean) * (r.r2.rating-u2_mean) ) AS nom,
sqrt( sum( (r.r1.rating - u1_mean)^2) * sum( (r.r2.rating - u2_mean) ^2)) AS denom,
u1, u2 WHERE denom <> 0
RETURN u1.name, u2.name, nom/denom AS pearson
ORDER BY pearson DESC LIMIT 100
- Neo4j 做推荐 (1)—— 基础数据
- Neo4j 做推荐 (2)—— 基于内容的过滤
- Neo4j 做推荐 (3)—— 协同过滤
- Neo4j 做推荐 (4)—— 基于内容的过滤(续)
- Neo4j 做推荐 (5)—— 基于类型的个性化建议
- Neo4j 做推荐 (6)—— 加权内容算法
- Neo4j 做推荐 (7)—— 基于内容的相似度量标准
- Neo4j 做推荐 (8)—— 协同过滤(利用电影评级)
- Neo4j 做推荐 (9)—— 协同过滤(人群的智慧)
- Neo4j 做推荐 (10)—— 协同过滤(皮尔逊相似性)
- Neo4j 做推荐 (11)—— 协同过滤(余弦相似度)
- Neo4j 做推荐 (12)—— 协同过滤(基于邻域的推荐)
在 “Neo4j 做推荐 (10)—— 协同过滤(皮尔逊相似性)” 上有 1 条评论
评论已关闭.